# Install the recommended bundle (UI + sealed sharing + extra loaders)
$ pip install "axon-rag[starter]"
# Run health check before your first query
$ axon --doctor
✓ Python 3.11 · Ollama reachable · llama3.1:8b cached · store writable
# First run auto-launches the setup wizard, then drops into the REPL
$ axon
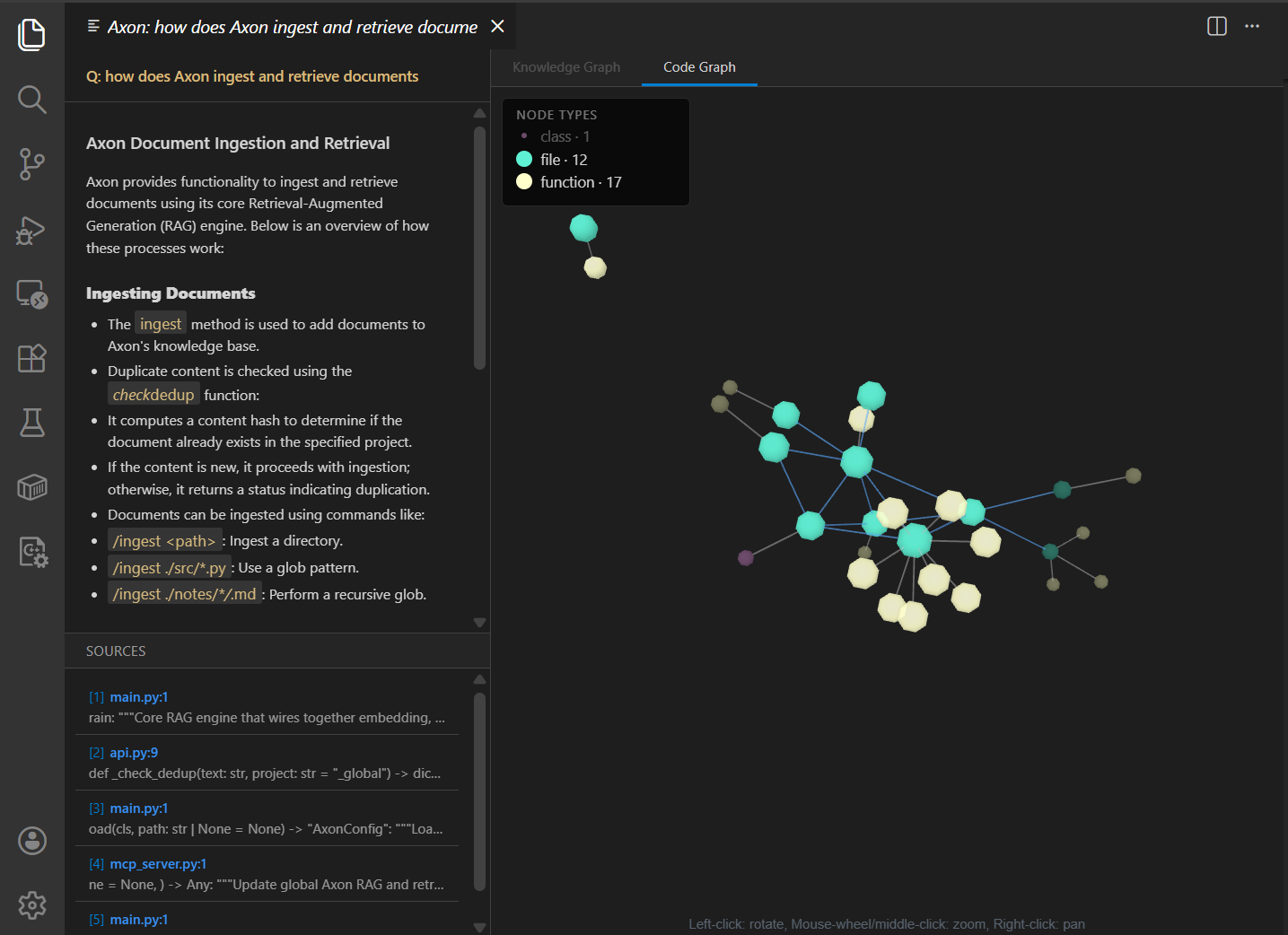
axon> /ingest ~/research/papers/
axon> /graph status
axon> What were the v0.3.2 graph backend changes?
axon> /graph retrieve "alice" --at 2025-06-01
axon> /share generate research alice --ttl-days 30
# Start the API server (set RAG_API_KEY first when binding to 0.0.0.0)
$ export RAG_API_KEY="$(openssl rand -hex 32)"
$ axon-api --host 0.0.0.0 --port 8000
# Query with structured citations enabled (default)
$ curl -X POST localhost:8000/query \
-H "Content-Type: application/json" \
-d '{
"query": "What were the v0.3.2 graph changes?",
"top_k": 8,
"include_citations": true
}'
# Response: { "response", "sources", "citations", "provenance", "settings" }
# Each citation: { marker, document_index, document_title, start_in_response, end_in_response }
# Point-in-time graph query — new in v0.3.2
$ curl -X POST localhost:8000/graph/retrieve \
-d '{
"query": "who led acme?",
"point_in_time": "2025-06-01T00:00:00Z",
"federation_weights": { "graphrag": 0.3, "dynamic_graph": 0.7 }
}'
# ~/.config/claude/mcp_servers.json — Claude Code, Codex CLI, Cursor, etc.
{
"mcpServers": {
"axon": {
"command": "axon-mcp",
"env": { "RAG_API_KEY": "$AXON_KEY" }
}
}
}
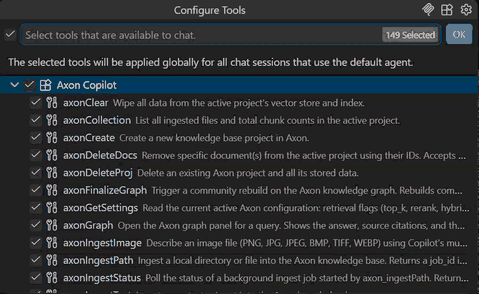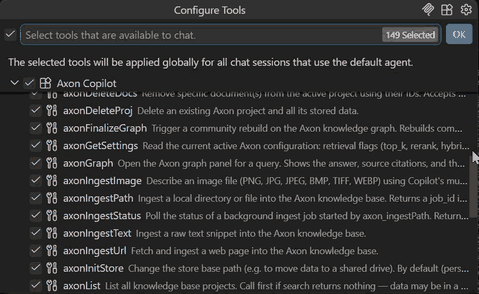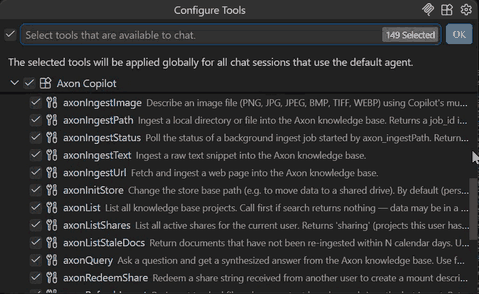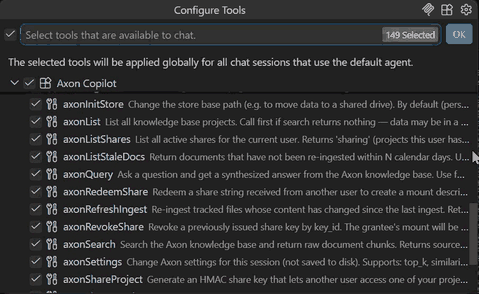
# 51 tools become available to your agent. A few highlights:
# query_knowledge — RAG query with citations
# search_knowledge — raw chunk search
# ingest_path — async ingest job
# graph_retrieve — point-in-time graph query (v0.3.2)
# graph_conflicts — list conflicted facts (v0.3.2)
# graph_finalize — community rebuild
# share_project — generate read-only share
# seal_project — encrypt at rest with AES-256-GCM
# governance_audit — query the audit log
# pip install "axon-rag[langchain]"
from axon import AxonBrain, AxonConfig
from axon.integrations.langchain import AxonRetriever
brain = AxonBrain(AxonConfig.from_yaml("config.yaml"))
retriever = AxonRetriever(brain=brain, top_k=5)
# Drop into any LangChain chain that takes a Retriever:
docs = retriever.invoke("What does the project do?")
# → list[langchain_core.documents.Document]
# Per-call override (one-off, doesn't mutate base)
docs = retriever.with_overrides({"hyde": True, "rerank": True}).invoke(query)
# All RAG features (hybrid, rerank, HyDE, multi-query, GraphRAG budget)
# apply automatically — same codepath as REST and REPL.
# pip install "axon-rag[llama-index]"
from axon import AxonBrain, AxonConfig
from axon.integrations.llama_index import AxonLlamaRetriever
from llama_index.core import VectorStoreIndex
from llama_index.core.query_engine import RetrieverQueryEngine
brain = AxonBrain(AxonConfig.from_yaml("config.yaml"))
retriever = AxonLlamaRetriever(brain=brain, top_k=5)
# Drop into any LlamaIndex query engine:
engine = RetrieverQueryEngine.from_args(retriever)
nodes = retriever.retrieve("What does the project do?")
# → list[NodeWithScore]
# Each NodeWithScore preserves Axon's hybrid + rerank scoring,
# plus is_web tagging for CRAG-Lite web fallback rows.
# pip install axon-rag
from axon import AxonBrain, AxonConfig
# Bring your own config or load from YAML
cfg = AxonConfig.from_yaml("config.yaml")
brain = AxonBrain(cfg)
# Ingest a directory (sync) or kick off an async job
brain.ingest_path("~/research/papers")
# Full RAG query — returns the LLM-synthesised answer string
answer = brain.query(
"What's new in v0.4.2?",
overrides={"hyde": True, "graph_rag": True}
)
# Need raw chunks instead? Skip the LLM:
results, diagnostics, trace = brain.search_raw(
"alice", overrides={"top_k": 10, "rerank": True}
)
# Citations + sources are stashed for the API to surface
print(brain._last_citations) # {"sources": [...], "citations": [...]}